Your developers are shipping more code than they were a year ago.
Probably a lot more.
And your test coverage is being asked to keep up with roughly the same headcount it had before Claude and Codex showed up.
That gap is the entire reason Amikoo exists.
I sat down with Ivan Barajas Vargas, who co-founded MuukLabs back in 2019 and spent six years building MuukTest before starting over from scratch on this one.
Here’s what he says changes when a QA agent sits between your pull requests and your test suite.
Amikoo sponsored this article. Everything below comes from my recorded conversation with their founder, Ivan Barajas Vargas, on episode A592 of the TestGuild Automation Podcast, plus their published materials. These are his claims and his numbers, not my benchmarks. I’m laying out what he told me. You decide whether it fits your team.
What is an AI QA agent?
An AI QA agent is a system that plans, writes, runs, and repairs tests using live context about your application, rather than following a fixed script. Unlike a general purpose coding assistant, it’s tuned for one job: keeping test coverage in sync with code that’s changing faster than a human team can follow.
That distinction is the pitch.
A general model will write you a Playwright test if you ask.
What it won’t do is tell you which twenty tests matter for the pull request that just landed, or notice that one selector change broke fifty three of your specs.
| Capability | Traditional Automation | General AI Coding Assistant | AI QA Agent (Amikoo) |
|---|---|---|---|
| Writes tests | You write them | Yes, on request | Yes, and suggests what to write |
| Application context | None | Whatever you paste in | Repo, tickets, docs, run history |
| Regression scope | Run everything | You decide | Suggests tests per pull request |
| Broken tests | Fix by hand | One at a time | Bulk fixes you approve |
| Output format | Your framework | Whatever you ask for | Playwright with page object model |
| Who stays in charge | The tester | The developer | The tester, reviewing and approving |
Still Not Sure? Try Our Test Tool Matcher
More AI means more testing, not less
I’ve been saying this at all my TestGuild IRL tour stops this year, so I was curious whether the vendor side sees the same thing. Ivan didn’t hedge.
“More testing, and testing becomes more critical. The main conversations we are having with potential customers are customers that are deploying 10X more code. So they are desperate to test faster.”
Ten times the code means more regressions, more integration surface, and more places for things to break that nobody thought to look at.
That’s Jevons Paradox landing on QA. Make a resource cheaper and you consume more of it, not less.
My own State of Automation survey data tracks the same curve.
AI adoption on testing teams went from roughly 2 percent in 2018 to more than 72 percent in 2025.
The tooling got cheap. The workload went up.
What actually happens in the first 15 minutes
Ivan walked me through it live on the recording, so this part I did watch.
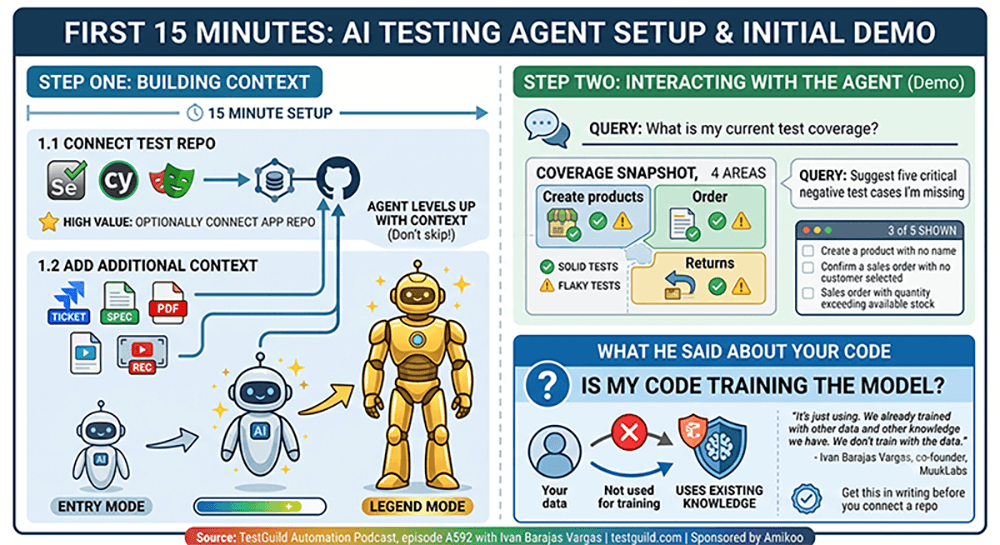
Step one is context. You connect a test repo in whatever framework you’re already using, Selenium, Cypress, or Playwright. Optionally you add the app repo, and Ivan is upfront that this is where the value jumps. You can also feed it Jira tickets, spec documents, PDFs, and screen recordings. He says setup runs about 15 minutes.
There’s a nice touch in the product where the agent visibly levels up as you add context, going from what they call entry mode to legend mode. Silly, but it makes the context requirement obvious to people who’d otherwise skip it.
Step two is asking it things. In the demo he typed a coverage question and it came back with a breakdown across four areas of the app, flagging which tests were solid and which were flaky. Then he asked for five negative test cases it was missing, and it proposed specifics like confirming a sales order with no customer attached and ordering quantity beyond available stock.
I asked the question every enterprise tester asks first. Is my code training your model?
“It’s just using. We already trained with other data and other knowledge we have. We don’t train with the data.”
Get that in writing during your own evaluation.
A podcast quote isn’t a contract, make sure to verify with the vendor before moving forward.
The token cost angle
This is the part I hadn’t heard another vendor address directly, and it’s why I wanted him on the show.
“Right now, with tokens getting crazy, we are seeing 10x more efficiency versus cloud using Opus.”
Their reasoning is that a general purpose model reprocesses far more context than a testing task needs.
Amikoo’s published benchmark puts a task at roughly 4,800 tokens against about 30,000 for a general model on the same test. Ivan also said the off the shelf MCP servers they tried were wasteful enough that they wrote their own for GitHub and other integrations.
Those are their numbers, run by them. I haven’t reproduced them and I’d tell you if I had.
What I will say is that the underlying problem is real.
I keep hearing from teams who blew through their token budget in week two and quietly shelved the whole AI testing experiment. Whichever vendor you end up with, ask about cost per test run at your volume before you ask about features.
The hot fix problem
When I worked in healthcare IT we’d get a hot fix dropped on us at 4pm Friday. Someone changed code in module B. Nobody could tell you whether test Z or test D touched module B.
So we ran everything. Every time. Because nobody could answer the question.
That’s the scenario Ivan says this is built for.
You point it at recent pull requests and it comes back with something like: run these 30, 18 are already automated, want me to write the other five?
Some teams are using it for quick throwaway checks on a PR, which they call ephemeral runs, without adding those tests to the permanent suite at all.
Flaky tests and who pushes the button
Testers have strong opinions about auto healing flaky tests, and they should. Silently fixing a broken test is how a real defect gets buried.
I asked Ivan whether flakiness is a tooling problem, a test design problem, or a genuine application problem in disguise.
“All of the above.”
Their Repair agent runs continuously. When something breaks it proposes a fix with a confidence score, something like 85 percent chance this is flaky versus 93 percent chance this is a real defect, then asks you which. If fifty tests broke because one selector moved, you can approve the fix across all of them at once instead of one at a time.
The design keeps the tester holding the pen. Which matters, because an agent that quietly repairs its own failures isn’t a safety net.
What he says not to hand over
This was my favorite answer, because he could easily have oversold here and didn’t.
“P0 and P1, I would still have a human always checking those.”
His model is to treat the agent like an intern or a new grad. It gets things wrong, you correct it, it improves. Your product also shifts underneath it, so what was right last quarter can be wrong now, which means the correcting never really stops.
“See it as a helper and have patience in that sense, and try to give it the right context as you would to a new teammate.”
Delegate P2 and P3 coverage. Keep humans on the critical path. That’s a policy you could defend in a release meeting.
Scaling automation is still a software project
Here’s the trap he sees teams fall into, and I see it too.
Getting 20 AI generated tests running is easy now.
Getting to 1,000 is an engineering project with architecture, test data management, and design patterns behind it.
“We see many teams breaking in that transition from a few dozens of tests to hundreds or thousands, because they saw early results with a few scripts, but they never thought about the architectural design you need to scale.”
Coding got cheap but as we all know architecture didn’t.
Which is exactly why he thinks the SDET role gets more valuable rather than less.
His advice for juniors is to stop optimizing for writing scripts and start learning to design test architecture at scale, because the job is now directing the agents. Test data management in particular still has no good automated answer.
For manual and non technical QA, his read is that agents are the new no code layer. You can build real automation now without writing code, but you’ll hit a ceiling fast if you don’t understand the patterns underneath.
Shipped now vs coming soon
Worth separating, since we recorded while several pieces were still in flight. As of our conversation:
Working today: context ingestion from repos, Jira, and documents. Coverage analysis. Test case suggestion. Playwright generation with page object model. Cloud test execution. The Repair agent with bulk fixes. PR based regression suggestions when you ask for them.
On the way, per Ivan: MCP connection so you can drive it from VS Code or Claude, Slack integration, and proactive PR detection where it flags the change and proposes the regression set before you ask. He put those weeks out at the time. Check the current state before you plan around them.
Who this fits and who it doesn’t
Good fit if: you’re on Playwright or willing to move there, your developers are shipping noticeably faster than your QA team can cover, you have a real maintenance burden on an existing suite, and you can get security approval to connect a repo.
Probably not your tool if: you need generated tests in Cypress or Selenium rather than Playwright, your organization won’t grant repo access to a third party, you’re testing mobile native apps, or you have a small stable suite that isn’t causing you pain. In that last case you don’t have the problem this solves.
Questions to ask before you buy any AI QA agent
Use these on Amikoo and on everyone else who pitches you this year:
- Cost per test run at your volume. Not the sticker price. What does 100 runs a day cost after three months?
- Data handling in writing. Training use, storage location, and who at the vendor can see your code.
- Test ownership. Can you read, edit, and run the output without the platform? Standard Playwright in your own repo is the bar.
- Repair transparency. Does it show the diff and ask, or just fix things?
- Scope selection. Can it tell you what to run for a specific change?
- Proof at scale. Ask for a reference running over 500 tests. Dozens are easy.
- Where it lives. If it doesn’t reach into Jira, GitHub, and Slack, adoption dies in week three.
Frequently asked questions
What is an AI QA agent? A system that plans, writes, runs, and repairs tests using live context about your application rather than a fixed script, with a human reviewing and approving its output.
How is Amikoo different from using Claude or Codex for tests? According to Ivan, the difference is specialization and cost. General models have no persistent product context, no repair memory, and no view of your coverage. Amikoo routes work across purpose built agents, which their benchmarks say cuts token use by roughly 10x on the same task.
What framework does Amikoo generate tests in? Playwright, using page object model structure, pushed into your own repo. It can read existing Selenium and Cypress repos for context, but generation is Playwright.
Will an AI QA agent replace testers? Ivan’s position, and mine, is no. It shifts the work toward deciding what matters, reviewing failures, and designing architecture that scales.
Can it fix flaky tests safely? It proposes fixes in bulk with a confidence score attached. Approval stays with you, which is how it should be on anything touching a critical path.
What should stay out of an agent’s hands? Ivan says P0 and P1 scenarios stay under human review. Delegate lower priority coverage and retrain as the product changes.
Try it and decide
Everything above is Ivan’s account of what Amikoo does. I found his answers unusually straight for a founder, especially the parts about what he wouldn’t delegate to his own product. But his word isn’t proof, and neither is mine.
There’s a free tier. Connect a repo, ask it where your coverage gaps are, and see whether the answer matches what you already suspect about your suite. Fifteen minutes will tell you more than any article will.
Try Amikoo: testgld.link/amikoo
Hear the full conversation: Episode A592 with Ivan Barajas Vargas
Seeing is believing. Tell them Joe sent you.